Large Blog Website Republishing Our Articles! 6
About a month ago, an editor at a large blog website followed one of my links in a comment there back here and offered to republish the story. I was already seeing increased traffic from that link on their site – like 10x more than my normal daily traffic – and it scared me. I don’t have the bandwidth to handle that sort of traffic and my Ruby on Rails blog software … er … pretty much sucks from a scalability perspective. What did I do?
Fixes for the Blog
First Steps – Improve Bandwidth Use
Like I said before, the Ruby on Rails blog software used here doesn’t scale very well. How bad is it? just 46 requests per second – really bad. As a comparison, plain apache can serve almost 2,000 requests per second. What are the differences?
Current Setup
I should really draw a picture. That would clarify things greatly.
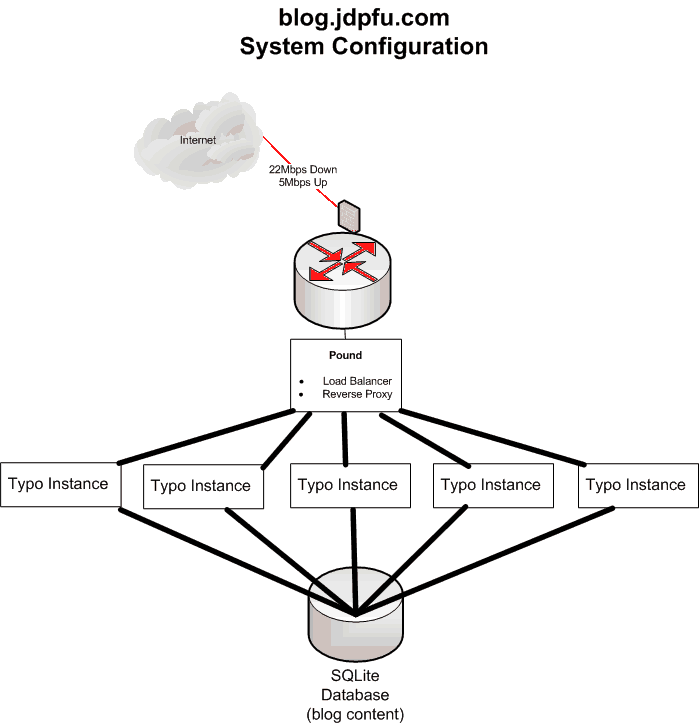
I have multiple instances of this blog running using Mongrel. Mongrel is the Ruby on Rails cluster manager tool and web server. It is written in Ruby and designed to make running multiple instances of a Ruby on Rails webapp easy. It works, but there are some downsides. I’ve run 1 instance, 2, 3, 6, and 9 instances to see how the scaling worked. More about that later, just know that Mongrel makes changing the number of instances pretty easy. There is no way to access any of the back end systems without using the reverse proxy. Further, those back-ends won’t respond to IPs from outside our subnet.
To access multiple back-end blog instances, I use a pretty well known software load balancer and reverse proxy, Pound. Pound is/was used by Slashdot.org, so I know it scales well. It is written in perl, a language I understand, and it is very lite-weight. Pound has a few really nice features that we use here at jdpfu.com too. These are:
- Reverse proxy and all that includes (security)
- Bad-URI filtering; seems lots and lots of external people want to access all sorts of unpublished webpages here, random characters, even things that we don’t use, like webmin or mysqladmin. We don’t use those tools and certainly wouldn’t allow them to be reached from the internet. If we had them, and we don’t, a user would need to use our VPN for any access.
- User-agent filtering to block content harvesters How many spam buy cheap handbags blog posts need to be pushed to a tiny blog like this anyway?
- SSL certificate front-end – this means I only need to install 1 HTTPS/SSL certificate for the entire jdpfu site and all the back-ends are protected.
- Load-Balancing – that means you hit port 80 and pound knows how to redirect that to any number of back-end servers to service the request.
- Cookie-based sticky servers. That means if you connect to a back-end server, your future connections are sent to that same server for session management, until the session expires.
Pretty cool stuff.
But pound is missing some things that the competition has and I could really use. Mainly, mod_compress or mod_gzip compatibility. A typical page from here is about 40K of javascript (yuck), CSS, and actual data. Compressed, that stuff would be under 10K easily. I really need to get a load-balancer that supports compression, but it also needs to support the other things.
Other Blog Issues
My little blog uses SQLite. For the last 5 yrs, that tool has worked well enough, but SQLite doesn’t scale well when you have multiple client processes. Sure, it works really well – even great – for 1 or 2 clients, but above that number and the file locking gets in the way of performance. I need to migrate to an SQL server of some type. I’d prefer Postres/SQL, but MySQL could work. Ruby on Rails supports both, but my attempts to migrate have failed. In fact, our SQLite DB for the blog claims to be corrupt so that even updating to a newer version of the blog software is failing. Ouch.
Blog Issues List
- RoR software (Ruby is considered a slower scripted language)
- LB that doesn’t support compression
- Database is stuck on the current version
Yes, we have some issues to solve here before we can allow lots and lots of traffic. I’ve considered migrating to different blog software. There are over 1,000 articles here, so some migration is needed.
Facts
Making changes without facts is bad, so I spent about a day running performance tests against a few different configurations to see which was optimal for the current situation. I changed the load balancer, the number of client processes to the SQLite DB, which machines were used for each. There were configurations that I would have liked to try, but couldn’t due to complexity or simply not having the time to setup. Anyway, by having performance tests and scripting them, I’ll know whether any improvements are actually improving anything. Facts are good.
Discussions
After negotiations with an editor, I gave her permission to re-publish the articles, edit the text as necessary and not include a link back to here. At the time, I hoped that would avoid the traffic issues, but there wasn’t any way to be certain. No date for the re-pub was provided, but I expected it would happen in a few days.
I don’t proof read this blog too much – you can see that in some of the articles. Wrong and missing words happen all the time. The best I can do is edit an article, walk away from it for 3+ hours, then re-read it later. This means I usually delay publishing articles for a day to give me a chance to proof read again. Sometimes those extra proof-reading sessions don’t happen. Other times the original article gets reworked or new data is created or found that needs to be incorporated. Regardless, the initial article is seldom the same as the published version, as you would expect.
Anyway, one of the articles was going to be re-published – the Security with the Hosts Files. Then I waited for the re-publish to happen … and waited. It took almost a month.
About 3 weeks later, LH had an article about Windows-PC maintenance. Someone there asked about maintenance for Linux systems, so I quickly wrote an article on that and provided a link back to the unpublished article here. It needed more thought before hitting the front-page here. That link, which was buried in a LH reply, got over 1000 unique visits in the first 12 hours. Much of that time, the article wasn’t even formally published here, but a draft version was being found and read. That’s the nature of public blogs with crappy software. So a different LH editor, Whitson, saw it and asked if I’d allow republishing. Sure – same conditions. Oddly, there was nothing more than a few emails, no contract. It was very informal – in my normal job, we try to stay informal, but always bring in lawyers to protect us and our partners and clients. LH feels really relaxed in their method. WG said he’d republish it the following Moday. When that didn’t happen, I assumed it was dropped and others had nixed the idea. I was wrong.
D-Day – July 1
Ok, that wasn’t the real D-Day, July 6, 1944 was, but both articles were re-published on LH about 2 hours apart on July 1, 2011. Seeing my words was a little thrilling and a little scary. Sure, I’d gone back and proof-read both those articles 10 times, yet there were still issues and mistakes. For those that I saw, I sent an email and those issues were fixed on LH. I’d provided a by-line that had a link to my online presence over at Identi.ca to let people find me, but I didn’t want to be a traffic hog. This blog is non-commercial – no ads, no sponsors. That identi.ca page has a link back to here, but I hoped that 2 levels of redirection would be enough to keep the traffic down. It worked. On July 1, traffic was about double the daily normal amount, but that amount is something my setup can easily handle.
I looked at the total views as LH counts them this morning for those articles. Respectable, but no where as much as the smartphone article posted the same day which got 3x more hits.
Here are the links to my version, theirs and the counted hits from their site.
- System Maintenance for Linux PCs
- What Kind of Maintenance Do I Need to Do on My Windows PC?
- LH Views: 18,677
- Security with the Hosts File
Planned Changes – Someday
Not too shabby, but I still need to get my little blog able to handle 10-20x more requests per second. That should be easy enough to accomplish with my current knowledge and the current hardware. I’m pretty certain that the planned new configuration will easily handle that traffic.
Nothing too great is planned. Just swap out pound for nginx and swap SQLite for MySQL. The machines that each of those processes run is still to be determined. We have a few options here.



If you’re looking to make due with the stuff you have already and not drastically expand…I’d trie using Jekyll http://jekyllrb.com/
It integrates with text based postings you can do right from any CVS…it’s flat html so no worries on bandwidth…and it will make what you have now work like bacon-greased lightening (much better than standard greased lightning).
So I’m still looking for a way to improve page load response. It has been busy here with bringing up additional RoR servers inside new virtual machines, working through Typo upgrade issues, and researching replacements for Mongrel (Thin is a replacement) and nginx to replace pound and migrating the data into a MySQL database.
A Few Articles
Anyway, here are some old performance articles:
Data Migration
Getting the data from Typo into any other blog is proving troublesome. I even brought up an Movable Type instance and played with it. The import tools are for wordpress with no RSS-feed options. Yuck.
Migrating Typo code from SQLite into MySQL has proven to be just as difficult. I do have another option to try that seems promising today. Someone wrote a plugin that allows migration of typo data between environments. So, migrating a development (SQLite) environment into a production (MySQL) environment seems possible. I do know that perl and python scripts claiming to convert SQLite dump files into MySQL-compatible input files all failed. I have some experience with this – I actually wrote a perl script that did this for a commercial product in the mid-late 1990s using ODBC connections. To be fair, we avoided DBMS specific extensions for our product. Further complications exist because we supported the main commercial DBMS servers of the time and MySQL was still quite the toy – it didn’t even support transactions. Oracle, DB2, Informix, MS-SQL, even MS-Access and a few others via ODBC drivers. Ah, the not-so-good old days.
Thin
I was able to bring up a Thin cluster pretty easily. Honestly, I wouldn’t have even looked, except that Mongrel refused to start on the 10.04 server and a few hundred call deprecated warnings were kicked out at every attempt. Mongrel is nice, but Thin sorta works pretty easily too.
Plus we had an emergency here yesterday, which needed immediate attention.
Ah I missed those two because of my holiday, I still haven’t caught up with my RSS feeds.
Allow me to congratulate you for the republish and good luck with the upgrades.
So we’ve been performing more testing here. Mainly to migrate to a newer version of the blog and not lose any content.
We have a new instance up and running with MySQL, so we did the same performance tests against that new instance and saw huge improvements – over 1000 requests/sec were handled without any issue – returned in under 1 second; a few took longer but more than 99% were served in under 1 second. Pretty nice.
At that point I started thinking a little. These tests were performed on our lab equipment and didn’t go through the WAN connection. Perhaps the WAN connection was the bottleneck? I ran the same tests against the production system, but avoided the WAN interface … it wasn’t as good as the new system, but it did handle 300 requests/second without any errors. Most requests were returned in under 1 second (99%). I did run a higher volume test and saw the errors rise to 50% quickly.
With the WAN router involved, we never served over 50 requests/second. Interesting. The servers and lab are all GigE connected, the main issue here is when the WAN.
The WAN connection has … er … significantly less bandwidth. It is only a 5Mbps uplink. That means if the average page is 15KB (reasonable) then about 40 requests/second can be served. So, the best answer is to get the average page to a smaller size. How? Compression.
Pound doesn’t support compression. Nginx does. There’s the quick answer. Our pound.conf file is non-trivial to put it nicely. It is over 200 lines long and deals with lots and lots of complexities. That just means we need to have a clear and working fall-back plan. Fine. Now to find the time to do this.
LH likes one of our tips about using Password Managers. Sweet.
This morning we switched over to using Nginx as the front-end of the site. Please report any issues that you see. We enabled compression for most of the content too, which should allow about 50% greater throughput. Individual requests should feel about that much quicker too.
With the compression, a 17K page is now 3.6K for the exact same content. Nice. We hope all the changes are positive and don’t cause any issues.